





Problem
Our team members often have questions about office policies, but they may feel hesitant to approach HR for answers. Meanwhile, HR’s process of looking up information in documents to respond to specific queries can be time-consuming. This highlights the need for a simpler and more accessible way to handle these common questions efficiently.
Solution
To tackle this challenge, we leveraged automation through an AI-powered chatbot. This strategy is aimed at streamlining the process, enabling rapid query responses, and offering convenience to both employees and HR. Our approach involves developing an AI chatbot integrated with Google Chat as we are using Google Workspace.
Tools, Technologies & Resources Used
The chatbot employs the RAG technique, along with following set of tools and technologies:

Overview
In today’s business environment, the demand for tailored intelligent chatbots is on the rise. Traditional bots have limitations as they can only handle a limited range of queries. There’s a need for more human-like intelligence that can deliver unique and precise responses based on a company’s data. This is where large language models (LLMs) come in. These AI models can comprehend and generate human-like language. Leveraging this capability, you can create responses tailored to your specific data. There are two main approaches to achieve this:
- LLM Fine-tuning
- Retrieval Augmented Generation (RAG)
The choice depends on various factors, but first, let’s understand what they are. LLM fine-tuning is a supervised learning process where you use a dataset of labeled examples to update the weights of an LLM and improve its performance for specific tasks. This is typically achieved by adjusting the model’s pre-trained weights with additional data or by fine-tuning specific layers of the model.
On the other hand, RAG is a technique that integrates external data with an LLM, providing the model with up-to-date unique contextual information to respond to user queries.
There are various factors to consider, including model size, data availability, resource constraints, etc., when choosing the strategy to build your bot. Typically, with large language models, RAG is preferred, while a hybrid approach can work well with medium and small models. However, for our use case, we opted for RAG due to the following advantages:
Firstly, fine-tuning requires more resources and time. When you fine-tune a model, the training data becomes integrated into the model itself, making it challenging to isolate or remove specific parts. Large language models cannot forget information. In contrast, vector stores allow you to add, update, and delete contents easily, enabling you to remove erroneous or outdated information as needed. Additionally, new data can be incorporated more frequently and seamlessly.
How Does RAG Work?
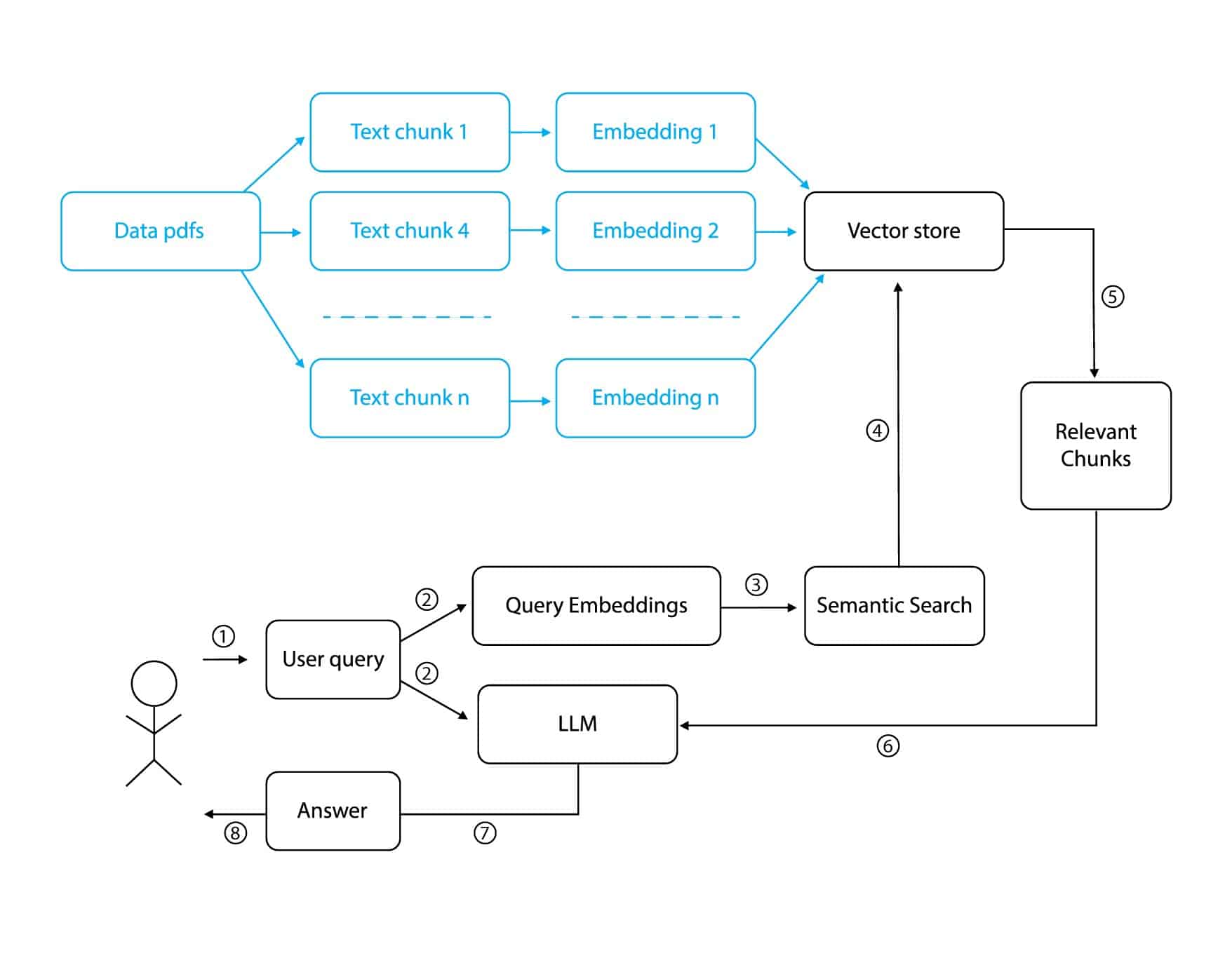
The RAG process can be broken down into the following steps:
1. Data Collection
This step involves gathering various sources such as FAQs, policies, user manuals, etc., which may be in formats like PDFs, docs, or others.
2. Content Extraction And Chunking
Next step after data collection is chunking. Chunking involves extracting and dividing content into manageable pieces because providing the entire data at once to large language models (LLMs) isn’t efficient. By breaking the data into smaller chunks, the relevant part can be easily extracted and sent to the LLM as needed, improving efficiency and processing speed.
This chunking process is crucial for fitting the data into your model effectively, ensuring accurate and clear results. Smaller chunks facilitate a finer match between the user’s query and the content, enhancing retrieval accuracy. In contrast, larger chunks introduce more noise, leading to reduced accuracy. Using smaller chunks also helps retrieve the most relevant information instead of processing entire documents at once. It’s important to note that larger chunk sizes can increase the input to the large language model (LLM), potentially slowing down response times.
There are various chunking strategies and different chunk sizes to consider. The ideal chunk size depends on your experimentation and system adjustments. You can try different token sizes such as 128, 256, 512, etc., and evaluate their performance to determine the optimal chunk size for your system.
3. Embeddings Creation
The data chunks, obtained by breaking down the information, are then transformed into numerical representations that computers can comprehend. These representations are placed in a high-dimensional space for quick comparison, a process not feasible with raw data. Additionally, they capture the semantic meaning and context of the text, enabling tasks such as search, recommendation systems, and sentiment analysis.
Embeddings refer to numerical representations of text in a vector space. They capture semantic information by placing words or phrases in a high-dimensional space where similar elements are closer together. This means that words with similar meanings or contexts have similar vector representations, enabling algorithms to understand their semantic relationships.
Embeddings are essential for the system to comprehend user queries based on the meaning of words, rather than simple word-to-word comparisons. This ensures that the responses provided are relevant to the user’s queries and speeds up the process of retrieving relevant information from the data. There are various methods for creating embeddings, and we are using the Sentence Transformer Model: all-MiniLM-L6-v2 to generate embeddings for our data.
4. Vectorstore
A vector store or knowledge database is a repository that stores the embeddings created in the previous step, enabling efficient retrieval. There are several options available, including local vector databases like Chroma or Faiss by Facebook, as well as online vector stores like Pinecone. For our application, we have chosen Pinecone vector store, utilizing Cosine similarity to measure the similarity between two vectors in an inner product space.
5. Handling User Queries
Now that our vector store is set up, let’s discuss how to handle user queries. When a user submits a query, it undergoes the same embedding model used for converting documents into embeddings for storage in our vector store, ensuring consistency across the system. The system then retrieves chunks from the database whose embeddings are most similar to the query embedding, employing measures like cosine similarity or Euclidean distance for comparison.
6. Generation Of Responses With LLM
In the final step, we feed the retrieved data from the database, along with the user query, into a large language model (LLM). There is a wide range of open-source and proprietary LLMs available for testing and selection, such as OpenAI’s GPT, Llama, Mistral, Flan T5, among others. Once we choose a specific LLM, we can further fine-tune parameters like temperature, top k, penalties, etc., to generate responses tailored to our specific needs.
In conclusion, the following figure summarizes the entire RAG process: we gather data, segment it into smaller chunks, generate embeddings, and store them in a vector store. When a user poses a query, we convert it into embeddings, retrieve relevant chunks, and then pass both the chunks and the query to an LLM. The LLM then generates a human-like response to answer the query.
Prototyping
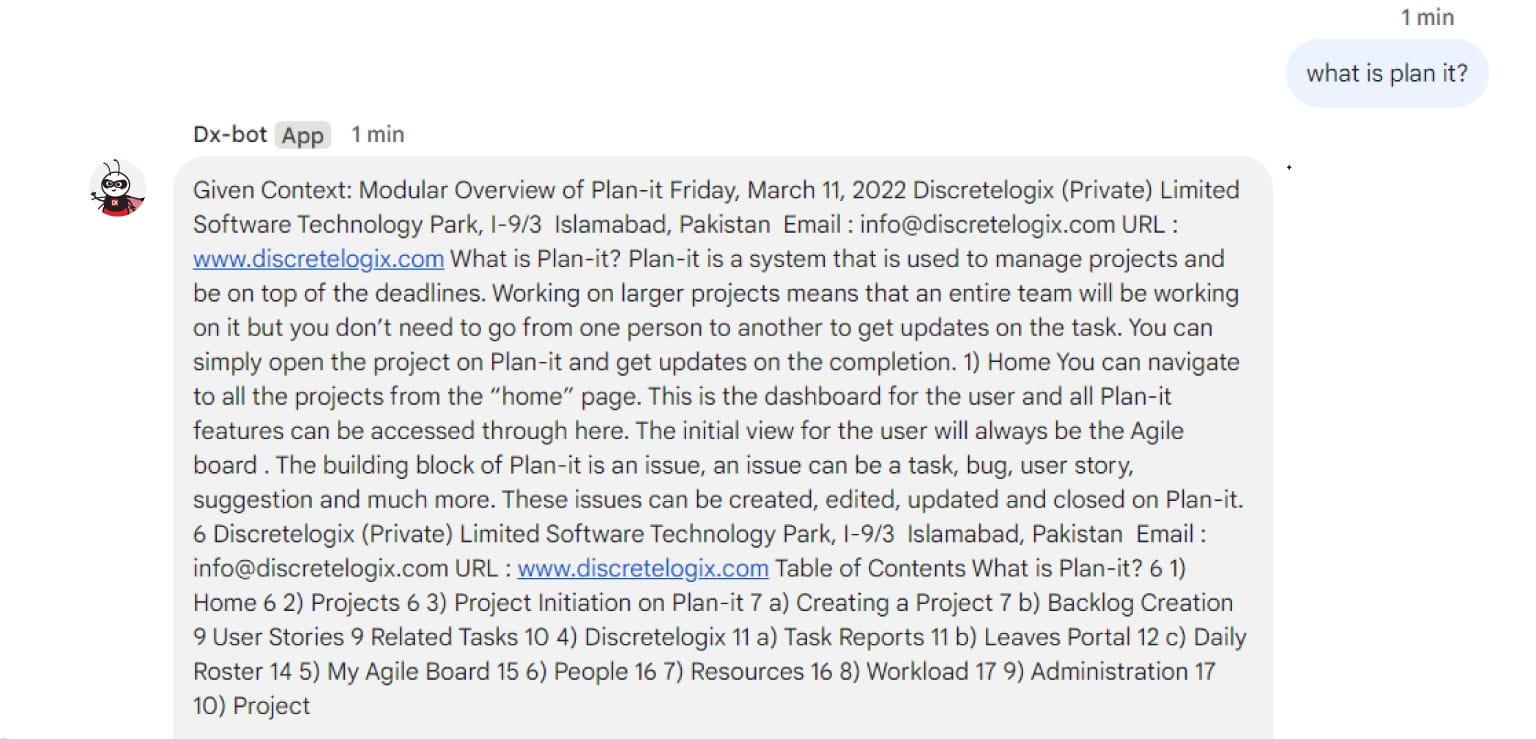
To prototype, we implemented RAG on Google Colab using our data. Initially, we worked with a smaller PDF dataset. As we began to achieve results, we combined our data and transitioned to the larger dataset. We utilized a Sentence Transformer model, which maps sentences and paragraphs to a 384-dimensional dense vector space suitable for tasks like clustering or semantic search. Consequently, we initialized the Pinecone vector store with 384 dimensions. We experimented with different LLMs and compared their responses, ultimately finding Mistral 7B to be the best fit for our use case. We utilized the Langchain framework, designed to simplify the creation of applications using large language models (LLMs). This framework facilitates the integration of external sources with LLMs, enabling our RAG application. It offers various chains for querying the LLM, such as the load QA chain and conversational retrieval chain. We specifically used the load QA chain for querying the LLM. Below are some comparisons related to our queries:
| Queries | LLama 2 LLM | Flan t5 LLM | Mistral 7b LLM |
|---|---|---|---|
| query=”Can spent time be more than estimated time according to provided context” | Response generated: “Yes, spent time can be more than estimated time according to the provided context. In fact, it is likely that the spent time will be more than the estimated time because the estimate was made without considering the actual time spent on each task. Therefore, the spent time will likely be higher than the estimated time.” | Response generated: “Yes” | Response generated: “Yes, spent time can be more than estimated time as the estimates are just that, estimates, and the actual time spent on a task may vary.” |
| query=”What is plan-it” | Response generated: “I don’t know the answer to that question as there is no information provided in the given text about what Plan-it is.” | Response generated: “Plan-it is a system that is used to manage projects and be on top of the deadlines.” | Response generated: “Plan-it is a system used to manage projects and stay on top of deadlines. It allows users to navigate to all projects from the home page and access various features, including creating and editing issues (tasks, bugs, user stories, etc.), managing user stories and related tasks, and viewing task reports and workload. Discretelogix is the company behind Plan-it, and they offer additional features such as a leaves portal, daily roster, and administrative tools.” |
Resources Utilized
| Resources | Specifications |
|---|---|
| Google Colab | T4 GPU
Available System RAM: 12.67 GB Available GPU RAM: 15 GB |
| Pinecone vector store | Dimensions : 384
Metric : Cosine K : 10 Free tier with a capacity for 100k records |
| Models | LLM: Llama 2, flan t5 xxl, Mistral 7b
Sentence Transformer Model: all-MiniLM-L6-v2 |
| Framework | Langchain |
Integration With Google Chat
Before proceeding with implementing RAG on GCP, we first needed to develop a basic application on Google Chat to receive and process queries. To achieve this, we utilized the Google Cloud Platform (GCP) and enabled the Google Chat API. Subsequently, we created a cloud function and integrated it with Google Chat.
Now, let’s delve into the RAG integration process, which can be divided into three main steps:
1. Formation Of Vector Store
This step involves creating and organizing the vector store, which was already completed during the prototype phase. We will continue to utilize the same Pinecone vector store for this purpose.
2. Extraction Of Data From The Vector Store
The subsequent step involves taking the query and retrieving relevant data from the vector store. To achieve this, we developed a Flask app on our local system. This app takes the query as input, generates its embeddings using the model from Hugging Face, extracts the relevant data from the Pinecone vector store using semantic analysis, and then returns it to the function. Following thorough testing, we dockerized the app and deployed it on Cloud Run. Subsequently, we integrated it with our Google Chat chatbot, enabling it to provide context upon receiving a query. It’s important to note that up to this point, no LLM integration has taken place.
3. Response Generation With LLM
For the third step of LLM integration, we utilized the Hugging Face inference API for Mistral 7B and integrated it through Langchain on a Cloud Function. This LLM receives both the context and the query, generates the response, and then we only output the response.
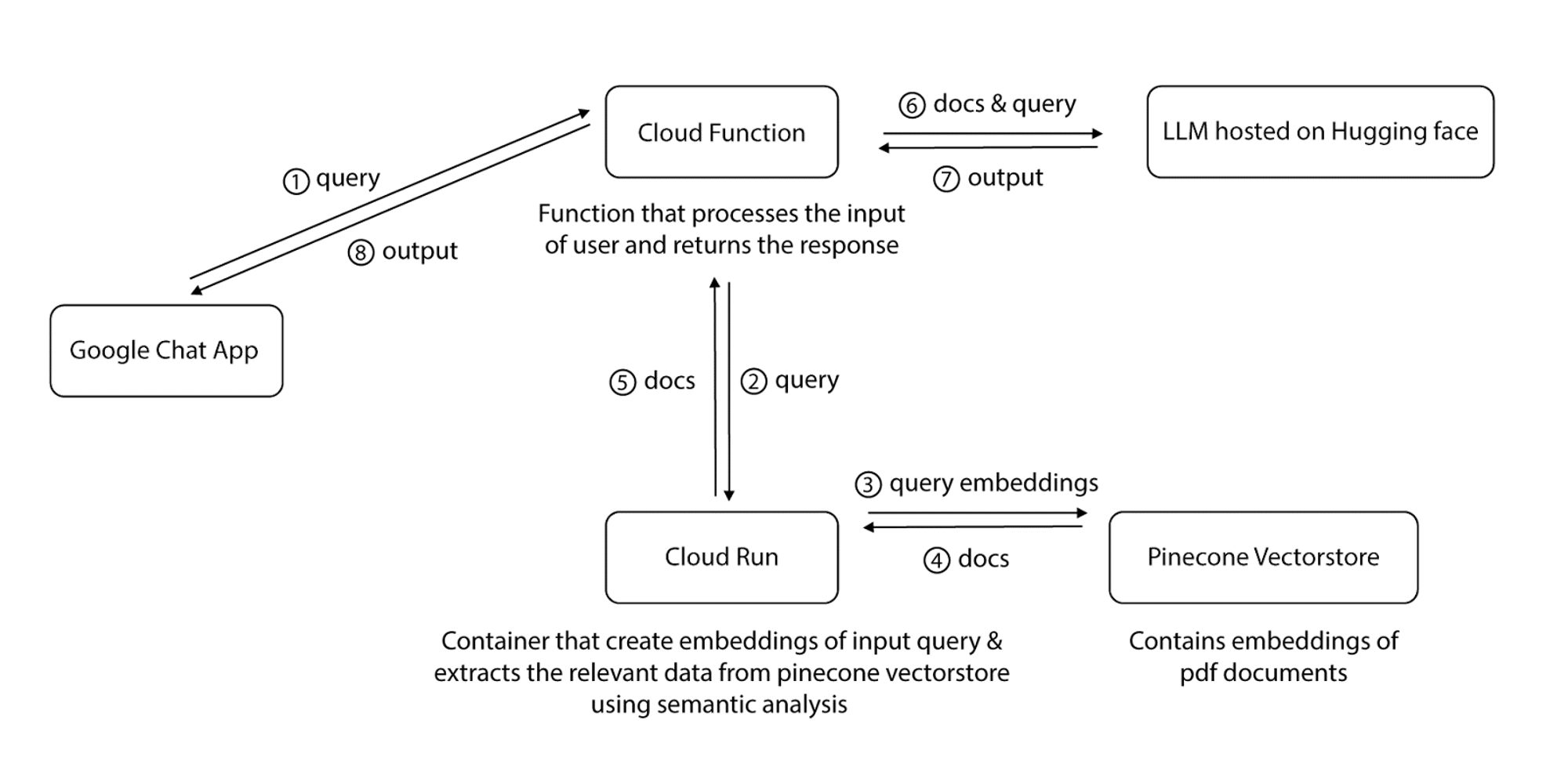
The overall process of integration can be visualized in the following diagram:
Resources Utilized
| Resources | Specifications |
| GCP | Cloud Run
Cloud Function Google chat api |
| Pinecone vector store | Dimensions : 384
Metric : Cosine K : 10 Free tier with a capacity for 100k records |
| Models | LLM: Mistral 7B
Sentence Transformer Model: all-MiniLM-L6-v2 |
| Framework | Langchain |
Conclusion
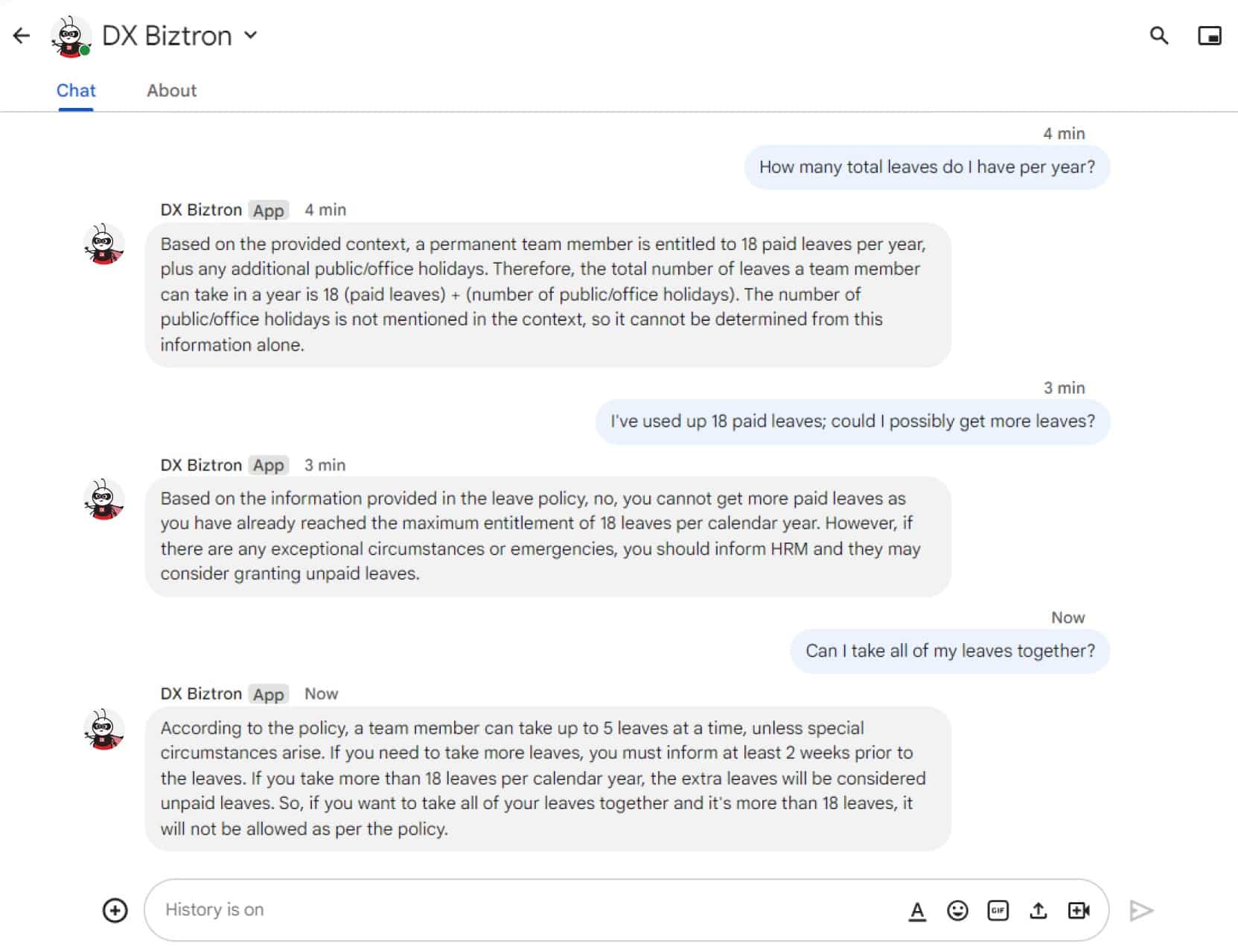
In conclusion, we began by gathering data, breaking it into chunks, creating embeddings, and storing them in our vector store. We developed a Google Chat app, connected it to a Google Cloud function, received queries from the chat, and sent these queries to a dockerized container. This container converts the queries into embeddings, performs a similar search, extracts relevant text from Pinecone vector store, and returns it. The relevant context, along with the original query, was then sent to the Mistral LLM through an inference API, and the resulting response was sent back to the user.
In the future, we plan to explore different vector stores, set up memory buffers, add greeting responses, and more. We’d love to hear your thoughts! Do you have any feedback or questions about the concepts we’ve discussed? Your input is valuable in improving our understanding.
